

neural network
目录
1 Model Representation 1
Let's examine how we will represent a hypothesis function using neural networks. At a very simple level, neurons are basically computational units that take inputs (dendrites) as electrical inputs (called "spikes") that are channeled to outputs (axons). In our model, our dendrites are like the input features \(x_{1},\ldots ,x_{n}\), and the output is the result of our hypothesis function. In this model our \(x_{0}\) input node is sometimes called the "bias unit." It is always equal to 1. In neural networks, we use the same logistic function as in classification, \(\frac{1}{1+e^{-\theta^{T}x}}\) yet we sometimes call it a sigmoid (logistic) activation function. In this situation, our "theta" parameters are sometimes called "weights".
Visually, a simplistic representation looks like:
\begin{equation} \label{eq:1} \begin{bmatrix}x_0 \\ x_1 \\ x_2 \\ \end{bmatrix}\rightarrow\begin{bmatrix}\ \ \ \\ \end{bmatrix}\rightarrow h_\theta(x) \end{equation}Our input nodes (layer 1), also known as the "input layer", go into another node (layer 2), which finally outputs the hypothesis function, known as the "output layer".
We can have intermediate layers of nodes between the input and output layers called the "hidden layers."
In this example, we label these intermediate or "hidden" layer nodes \(a_{0}^{2},\ldots ,a_{n}^{2}\) and call them "activation units."
\begin{align*}& a_i^{(j)} = \text{"activation" of unit $i$ in layer $j$} \\& \Theta^{(j)} = \text{matrix of weights controlling function mapping from layer $j$ to layer $j+1$}\end{align*}If we had one hidden layer, it would look like:
\begin{equation} \label{eq:2} \begin{bmatrix}x_0 \\ x_1 \\ x_2 \\ x_3\end{bmatrix}\rightarrow\begin{bmatrix}a_1^{(2)} \\ a_2^{(2)} \\ a_3^{(2)} \\ \end{bmatrix}\rightarrow h_\theta(x) \end{equation}The values for each of the "activation" nodes is obtained as follows:
\begin{align*} a_1^{(2)} = g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3) \\ a_2^{(2)} = g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3) \\ a_3^{(2)} = g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3) \\ h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)}) \\ \end{align*}This is saying that we compute our activation nodes by using a \(3\times 4\) matrix of parameters. We apply each row of the parameters to our inputs to obtain the value for one activation node. Our hypothesis output is the logistic function applied to the sum of the values of our activation nodes, which have been multiplied by yet another parameter matrix \(\Theta^{(2)}\) containing the weights for our second layer of nodes.
Each layer gets its own matrix of weights, \(\Theta^{(j)}\)
The dimensions of these matrices of weights is determined as follows:
If network has \(s_{j}\) units in layer \(j\) and \(s_{j+1}\), then \(\Theta^{(j)}\) will be of dimension \(s_{j+1}\times(s_{j} + 1)\).
The \(+1\) comes from the addition in \(\Theta^{(j)}\) of the "bias nodes," \(x_{0}\) and \(\Theta_{0}^{(j)}\). In other words the output nodes will not include the bias nodes while the input will. The following image summarizes our model representation:

Example: If layer 1 has 2 input nodes and layer 2 has 4 activation nodes. Dimension of \(\Theta^{(1)}\) is going to be \(4\times 3\) where \(s_{j} = 2\) and \(s_{j+1} = 4\), so \(s_{j+1}\times (s_{j} + 1) = 4\times 3\).
2 Model Representation II
To re-iterate, the following is an example of a neural network:
\begin{align*} a_1^{(2)} = g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3) \\ a_2^{(2)} = g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3) \\ a_3^{(2)} = g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3) \\ h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)}) \\ \end{align*}In this section we'll do a vectorized implementation of the above functions. We're going to define a new variable \(z_{k}^{(j)}\) that encompasses the parameters inside our \(g\) function. In our previous example if we replaced by the variable \(z\) for all the parameters we would get:
\begin{align*}a_1^{(2)} = g(z_1^{(2)}) \\ a_2^{(2)} = g(z_2^{(2)}) \\ a_3^{(2)} = g(z_3^{(2)}) \\ \end{align*}In other words, for layer \(j=2\) and node \(k\), the variable \(z\) will be:
\begin{equation} \label{eq:3} In other words, for layer j=2 and node k, the variable z will be: \end{equation}The vector representation of \(x\) and \(z^{j}\) is:
\begin{align*}x = \begin{bmatrix}x_0 \\ x_1 \\\cdots \\ x_n\end{bmatrix} &z^{(j)} = \begin{bmatrix}z_1^{(j)} \\ z_2^{(j)} \\\cdots \\ z_n^{(j)}\end{bmatrix}\end{align*}Setting \(x=a^{(1)}\), we can rewrite the equation as:
\begin{equation} \label{eq:4} z^{(j)} = \Theta^{(j-1)}a^{(j-1)} \end{equation}We are multiplying our matrix \(\Theta^{(j-1)}\) with dimensions \(s_{j}\times(n+1)\) (where \(s_{j}\) is the number of our activation nodes) by our vector \(a^{(j-1)}\) with height \(n+1\). This gives us our vector \(z^{(j)}\) with height \(s_{j}\). Now we can get a vector of our activation nodes for layer \(j\) as follows:
\begin{equation} \label{eq:5} a^{(j)} = g(z^{(j)}) \end{equation}Where our function \(g\) can be applied element-wise to our vector \(z(j)\) .
We can then add a bias unit(equal to 1) to layer \(j\) after we have computed \(a^{(j)}\). This will be element \(a_{0}^{(j)}\) and will be equal to 1. To compute our final hypothesis, let's first compute another \(z\) vector:
\begin{equation} \label{eq:7} z^{(j+1)} = \Theta^{(j)}a^{(j)} \end{equation}We get this final \(z\) vector by multiplying the next theta matrix after \(\Theta^{(j-1)}\) with the values of all the activation nodes we just got. This last theta matrix \(\Theta^{(j)}\) will have only one row which is multiplied by one column \(a^{(j)}\) so that our result is a single number. We then get our final result with:
\begin{equation} \label{eq:6} h_\Theta(x) = a^{(j+1)} = g(z^{(j+1)}) \end{equation}Notice that in this last step, between layer \(j\) and layer \(j+1\), we are doing exactly the same thing as we did in logistic regression. Adding all these intermediate layers in neural networks allows us to more elegantly produce interesting and more complex non-linear hypotheses.
3 Examples and Intuitions I
A simple example of applying neural networks is by predicting \(x_{1}\) AND \(x_{2}\), which is the logical 'and' operator and is only true if both \(x_{1}\) and \(x_{2}\) are 1.
The graph of our functions will look like:
\begin{align*}\begin{bmatrix}x_0 \\ x_1 \\ x_2\end{bmatrix} \rightarrow\begin{bmatrix}g(z^{(2)})\end{bmatrix} \rightarrow h_\Theta(x)\end{align*}Remember that \(x_{0}\) is our bias variable and is always 1.
Let's set our first theta matrix as:
\begin{equation} \label{eq:9} \Theta^{(1)} =\begin{bmatrix}-30 & 20 & 20\end{bmatrix} \end{equation}This will cause the output of our hypothesis to only be positive if both \(x_{1}\) and \(x_{2}\) are 1. In other words:
\begin{align*}& h_\Theta(x) = g(-30 + 20x_1 + 20x_2) \\ \\ & x_1 = 0 \ \ and \ \ x_2 = 0 \ \ then \ \ g(-30) \approx 0 \\ & x_1 = 0 \ \ and \ \ x_2 = 1 \ \ then \ \ g(-10) \approx 0 \\ & x_1 = 1 \ \ and \ \ x_2 = 0 \ \ then \ \ g(-10) \approx 0 \\ & x_1 = 1 \ \ and \ \ x_2 = 1 \ \ then \ \ g(10) \approx 1\end{align*}So we have constructed one of the fundamental operations in computers by using a small neural network rather than using an actual AND gate. Neural networks can also be used to simulate all the other logical gates. The following is an example of the logical operator 'OR', meaning either \(x_{1}\) is true or \(x_{2}\) is true, or both:

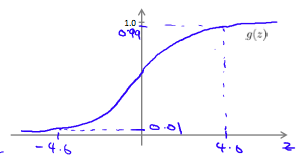
where \(g(z)\) is the following:
4 Examples and Intuitions II
The \(\Theta^{(1)}\) matrices for AND, NOR, and OR are:
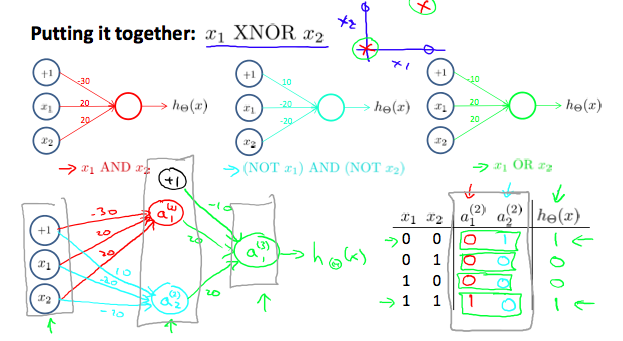
\begin{align*}AND:\\\Theta^{(1)} &=\begin{bmatrix}-30 & 20 & 20\end{bmatrix} \\ NOR:\\\Theta^{(1)} &= \begin{bmatrix}10 & -20 & -20\end{bmatrix} \\ OR:\\\Theta^{(1)} &= \begin{bmatrix}-10 & 20 & 20\end{bmatrix} \\\end{align*}We can combine these to get the XNOR logical operator (which gives 1 if x1 and x2 are both 0 or both 1).
\begin{align*}\begin{bmatrix}x_0 \\ x_1 \\ x_2\end{bmatrix} \rightarrow\begin{bmatrix}a_1^{(2)} \\ a_2^{(2)} \end{bmatrix} \rightarrow\begin{bmatrix}a^{(3)}\end{bmatrix} \rightarrow h_\Theta(x)\end{align*}For the transition between the first and second layer, we'll use a \(\Theta^{(1)}\) matrix that combines the values for AND and NOR:
\begin{equation} \label{eq:10} \Theta^{(1)} =\begin{bmatrix}-30 & 20 & 20 \\ 10 & -20 & -20\end{bmatrix} \end{equation}For the transition between the second and third layer, we'll use a \(\Theta^{(2)}\) matrix that uses the value for OR:
\begin{equation} \label{eq:11} \Theta^{(2)} =\begin{bmatrix}-10 & 20 & 20\end{bmatrix} \end{equation}Let's write out the values for all our nodes:
\begin{align*}& a^{(2)} = g(\Theta^{(1)} \cdot x) \\& a^{(3)} = g(\Theta^{(2)} \cdot a^{(2)}) \\& h_\Theta(x) = a^{(3)}\end{align*}And there we have the XNOR operator using a hidden layer with two nodes! The following summarizes the above algorithm:
5 Multiclass Classification
To classify data into multiple classes, we let our hypothesis function return a vector of values. Say we wanted to classify our data into one of four categories. We will use the following example to see how this classification is done. This algorithm takes as input an image and classifies it accordingly:
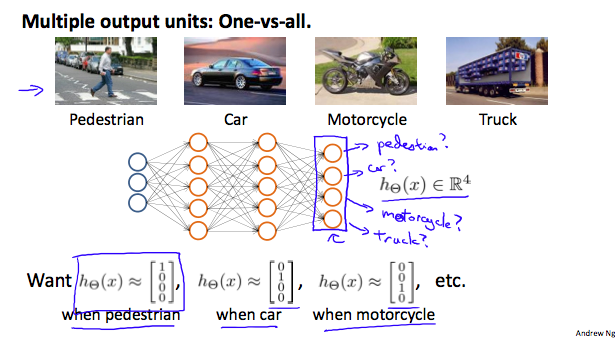
We can define our set of resulting classes as y:

Each \(y^{(i)}\) represents a different image corresponding to either a car, pedestrian, truck, or motorcycle. The inner layers, each provide us with some new information which leads to our final hypothesis function. The setup looks like:
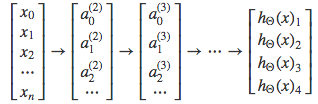
Our resulting hypothesis for one set of inputs may look like:
\begin{equation} \label{eq:12} h_\Theta(x) =\begin{bmatrix}0 \\ 0 \\ 1 \\ 0 \\\end{bmatrix} \end{equation}In which case our resulting class is the third one down, or \(H_{\Theta}(x)_{3}\), which represents the motorcycle.